paper-reading-group
LEARNING TO DESCRIBE SCENES WITH PROGRAMS
Paper - https://openreview.net/pdf?id=SyNPk2R9K7
Talk at MIT on Neurosymbolic AI - https://www.youtube.com/watch?v=4PuuziOgSU4&t=1749s
Motivation

- Recent AI systems for scene understanding have made impressive progress on detecting,segmenting, and recognizing individual objects
- In contrast, the problem of understanding high-level, abstract relations among objects is less studied
- Aims to tackle the problem of understanding higher-level, abstract regularities such as repetition and symmetry by representing scenes as scene programs
- Deep neural networks trained in an end-to-end fashion to output quantities such as count give really performance. Reason being concept (colors, shape) and reasoning (count) are entangled in the representations learnt by neural networks
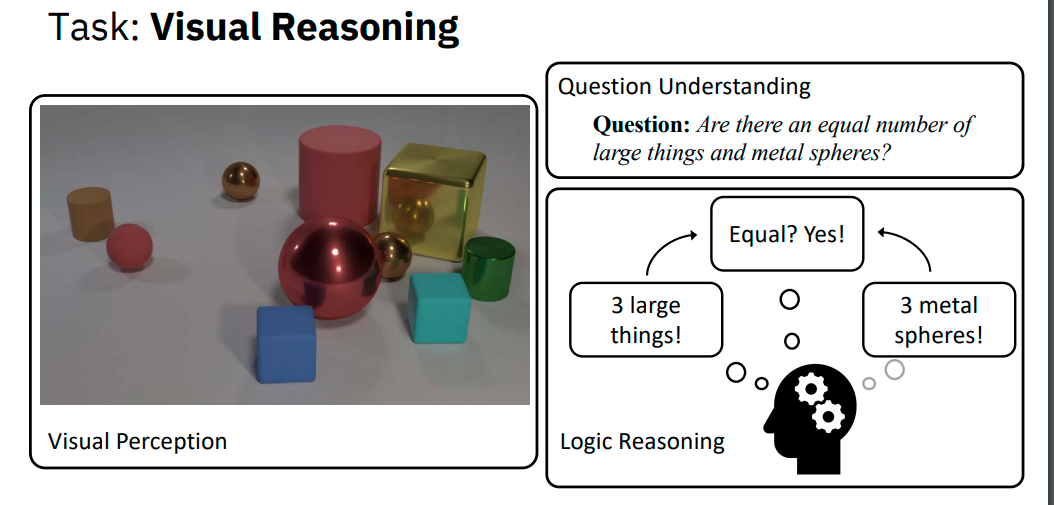
How we go about understanding images
Key Contributions
- Scene Programs - representing a scene via a symbolic program for its objects, attributes and their relations
- A models that infers such scene programs by exploiting a hierarchical, object-based scene representation
Method Summary
- Represent scenes as scene programs
- Define a domain specific language for scenes, capturing both objects with their geometric and semantic attributes, as well as program commands such as loops to enforce higher-level structural relationships
- Infer the scene program of an image of a complex scene via a hierarchical bottom-up
approach (deep neural networks used for each step) -
- Parse the image into individual objects and infer their attributes, resulting in the object representation
- Organize these objects into different groups, i.e. the group representation, where objects in each group fall into the same program block
- Describe each group with a program, and combine these programs to get the program representation for the entire scene
# Method
- An object parser predicts the segmentation mask and attributes for each object in the image
- A group recognizer predicts the group that each object belongs to
- A program synthesizer generates a program block for each object group

## A DOMAIN-SPECIFIC LANGUAGE (DSL) FOR SCENES

- Contains 3 primitive commands (cube, sphere,cylinder) and 2 loop structures (for, rotate)
- The positions for each object are defined as affine transformations of loop indices, while the colors are more complicated functions of the loop indices, displaying alternating (modular) and repeating (division) patterns
- Program blocks to further reduce complexity. Each type of program block is an production instance of the Statement token, and objects that belong to the same block form a group For example, in this work the program blocks include single objects, layered for loops of depth ≤ 3, and single-layer rotations of ≤ 4 objects
### Program Structure

- A program block is represented as a matrix of size N × 14 where N is the number of program commands
- 14 dimensional vector into 4 parts -
- program token (index 0)
- iteration arguments (index 1-3)
- position arguments (index 4-6)
- color arguments (index 7-13)
## OBJECT PARSING
- Object attributes are used as an intermediate representation between image space and structured program space
- Parsing individual objects from the input image consists of two steps: mask prediction and attribute prediction
- For each object, its instance segmentation mask is predicted by a Mask R-CNN. Next, the mask is concatenated with the original image, and sent to a ResNet-34 to predict object attributes.
- Object attributes used are shape, size, material, color and 3D coordinates. Each attribute is encoded as a one-hot vector, except for coordinates. The overall representation of an object is a vector of length 18
## GROUP DETECTION
- To answer the question -
Given an input object, which objects are in the same group with this object?
- Tells us which objects form a group that can be described by a single program block
- The input to the model consists of three parts: the original image, the mask of the input object, and the mask of all objects. These three parts are concatenated and sent to a ResNet-152 followed by fully connected layers
- The output contains two parts: a binary vector g where g[i] = 1 denotes object i in the same group with the input object, and the category c of the group, representing the type of program block that this group belongs to
## NEURAL PROGRAM SYNTHESIS
- The final step in our model is to generate program sequences describing the input image by having a program block for each group
- seq2seq LSTM structure with an encoder-decoder structure and attention mechanism
- The input sequence is a set of object attributes that form a group,which are sorted by their 3D coordinates
- The output program consists of two parts -
- Program tokens are predicted as a sequence as in neural machine translation
- Program parameters are predicted by a MLP from the hidden state at each time step
- At each step, a token t is predicted as well as a parameter matrix P, which contains predicted parameters for all possible tokens
- Then P[t] as the output parameter for this step
### Combining group prediction with program synthesis

- Sample 10 times and stop when a correct program is generated
- A correct program is one which can recover the scene attributes upon execution
# Experiments
## Data
- Each scene consists of a few groups, where objects in the same group can be described by a program block.
- The groups are sampled from predefined program primitives with multi-layered translational and rotational symmetries. Further, we also incorporate rich color patterns are also incorporated into the primitives
- Each image has at most 2 groups of multiple objects, in addition to many groups of a single object
- 20000 training images, 500 testing images
## Visual Program Synthesis

Comparison of method with -
Search-based heuristic grouping method (HG)

Derender LSTM - removes group recognition and instead synthesizes programs from all object attributes
CNN-LSTM encoder-decoder - directly synthesizes programs from the input image in an end-to-end manner. Decoder predicts a token as well as a parameter matrix at each time step
### Results
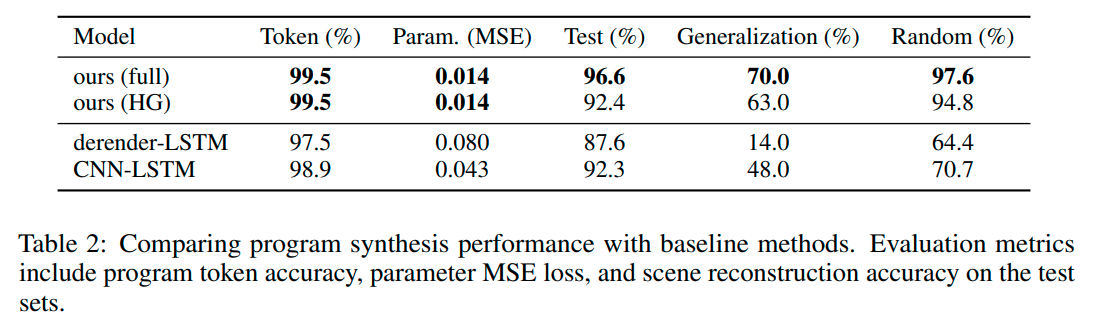
Reconstruction accuracy - percentage of programs that correctly reconstruct the original image
Program token accuracy - percentage of correctly predicted tokens
Parameter loss - mean-squared error of parameter prediction
### Tackling ambiguous input

### Program synthesis from partial observations

- Given an input image, object instance masks are generated and those with area below a certain threshold are removed, so that the remaining objects can be correctly recognized
- These objects form the partial observation of the model, from which the program synthesizer generates a program block which correctly describes the scene, including (partially) occluded objects
- The flexibility of the neural program synthesizer allows recognition of the same program pattern given different partial observations
## IMAGE EDITING
### Image editing via program representation

### Real image extrapolation

## VISUAL ANALOGY MAKING
- An input image is converted to a new image given other reference images
-
The reference is an image pair and the question is -
If B follows A, then what should follow C?
- An encoder R and an input image c with reference pair (a, b), we set R(d) = R(c) + R(b) − R(a) and decode R(d) to get the output
