paper-reading-group
Graph Neural Networks
Graphs
A Simple Graph:
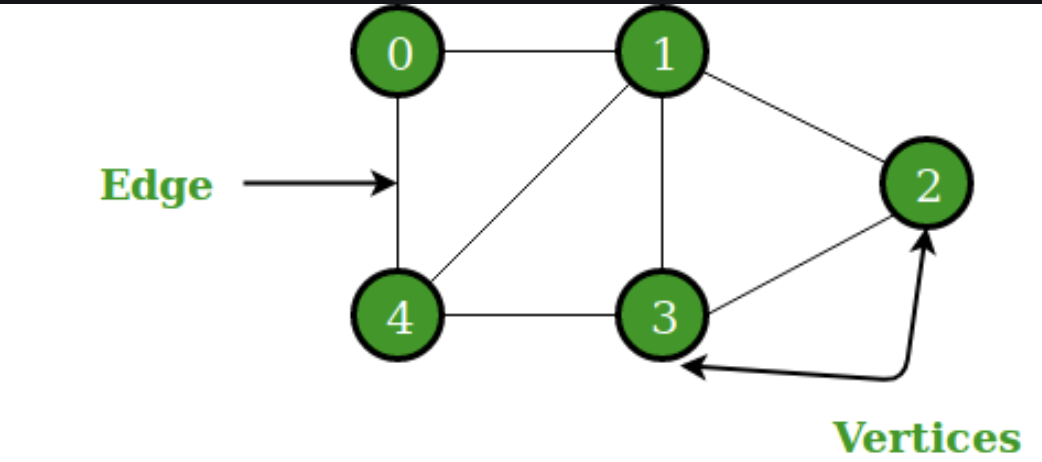
Figure 1: A Simple Graph
Graphical Communities:

Figure 2: Community Graphs
Etc.
When to use Graph Neural Networks?
- Some interaction between graphical entities is required and an embedding representation will be better.
Some Examples :-
- Social Network Relationships.
- Textual Relational Reasoning.
- Interaction Prediction
- Chemistry/Biology/etc
Graph Neural Networks
Basic definitions
- A Graph (V, E). Often represented through the adjacency matrix i.e., (V, V).
- Nodes can have two features:
- Some features of its own:- attributes, embedding, etc
- Related nodes, position in the graph, etc.
- Edges:
- Direction
- Weight
Goal
- For every node v, we would like to develop a representation (embedding) $h_{v} \ \epsilon\ \Reals^{d}$
- Once we have $h_{v}$, it can be used for other downstream tasks like node classification, community detection, graph embedding, etc.
DeepWalk
- Recap of skip-gram:
- Given a sequence of words: $W_{1}^{n} = (w_0, w_1, …., w_n)\ where\ w_i \epsilon\ V$
-
We would like to maximize the $P(w_n \ w_0, w_1, …, w_{n-1})$
- How do we transfer this approach to Graphs?
- Perform Random Walks on the graph.
- How do we relax random walks so that it can work with huge length walks?
-
Minimize $-log P({w_{i-w},…., w_{i+w} \Phi (v_{i}) }$
-
- Unsupervised
- Things that could be added:
- Loss which induces better embeddings
- Instead of walking, aggregation
Neighborhood Aggregation
- A neighborhood aggregation function
- $h_{v} = f(x_v, x_{co[v]}, h_{ne[v]}, x_{ne[v]})$
- All have different weight matrices here^
- Output function
- $o_v = g(x_v, h_v)$
- Compute losses and train
- $\sum_{i=1}^{p} criterion(t_i, o_i)$
- Note: Not an sum, but a average.
-
Generate embeddings
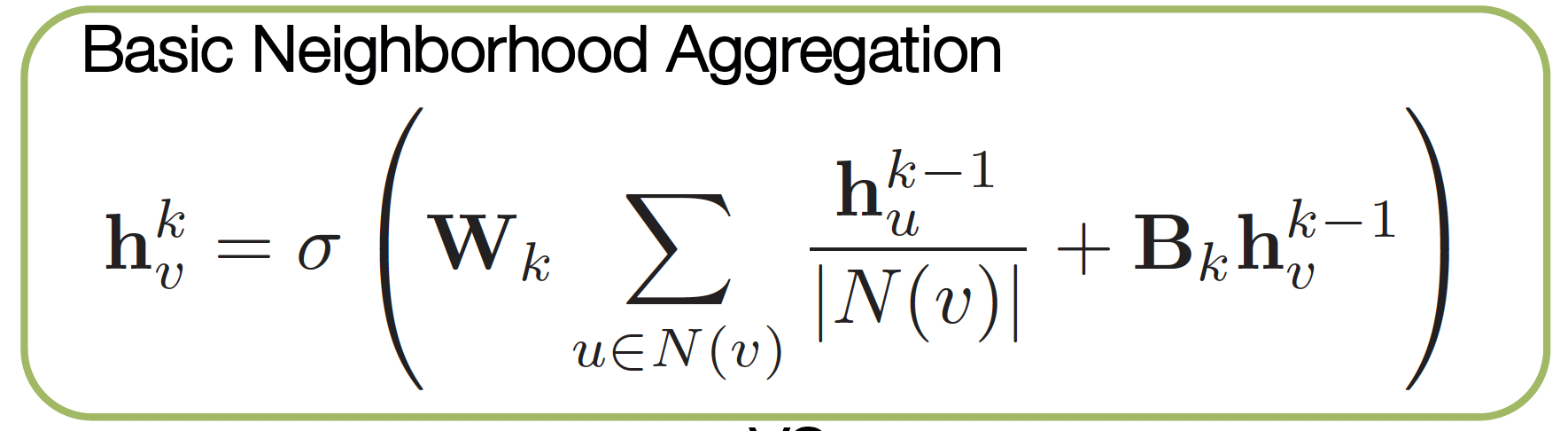
Figure 3: Basic Neighborhood aggregation
Graph Convolutional Neural Networks
- Parameter sharing between self and neighborhood embeddings

Figure 4: Graph Convolutional Network based Graph Aggregation
Disadvantages:
- Need the whole graph laplacian!
- Every step requires loading the whole graph into memory. We should sample graph neighborhoods.
Graph Sage (Sample and Aggregate)
-
Sample a neighborhood
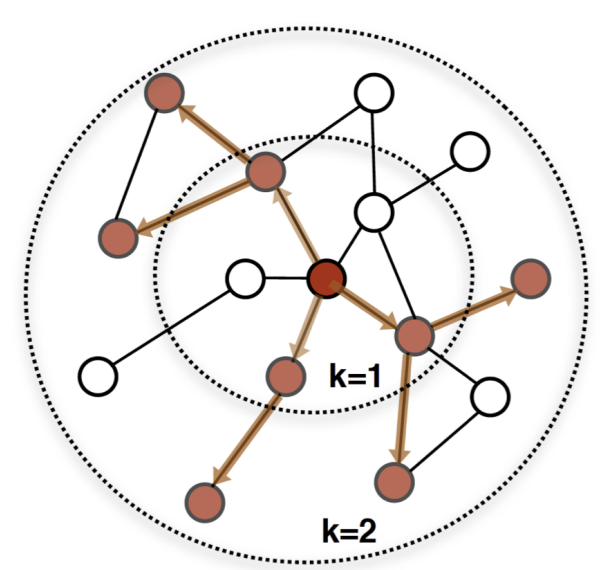
-
Aggregate across k neighborhoods (here, k=2)

-
Predict output based on context and label using g

- Things to note:
- Aggregation function could be any kernel, for e.g.
- Simple Average
- Pooling
- LSTM (in the case of an evolving structure)
- Aggregation function could be any kernel, for e.g.
- Advantages of this approach:
- Sampling means not requiring to load the whole graph.
- Variation across what can be the aggregation function.
- Very useful in scenarios where high throughput performance is requires on evolving graphs.
Few Applications
- Citation Networks
- Goal is to predict paper subject categories.
- Reddit posts classification (into subreddits)
- Connections based on user activity.
References
- F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2009
- B. Perozzi, R. Al-Rfou, and S. Skiena. Deepwalk: Online learning of social representations. In KDD, 2014.
- W. L. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” NIPS 2017, pp. 1024–1034, 2017
- T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” ICLR 2017, 2017