paper-reading-group
Efficient adaption for end-to-end Vision-Based Robotic Manipulation
Ryan Julian, Benjamin Swanson, Gaurav S. Sukhatme, Sergey Levine, Chelsea Finn, Karol Hausman
Problem
- Most of the current robotic learning systems are set up with fixed policies, which are not fine-tuned/adapted while in use.
- Generally, even if RL policies are used while deploying these robotic systems they tend to be static i.e. if you want to adapt to a change then these policies would need to retrained again.
- Now, there are works that adapt based on the visual input, like a model pre-trained on ImageNet and then fine-tuning it to a specific task, but there are none that adapt to the change in motor skills.
- Why this is important?
- Consider a set of objects which were used for training the whole system.
- Now if you have a new object which the model hasn’t seen during deployment, then the policy which was not adapted/fine-tuned will fare far worse than the one which did adapt.
- This can be useful in a lot of real-world applications as well like Self driving cars.
Approach
They have tried to adapt the policy to change in two different aspects
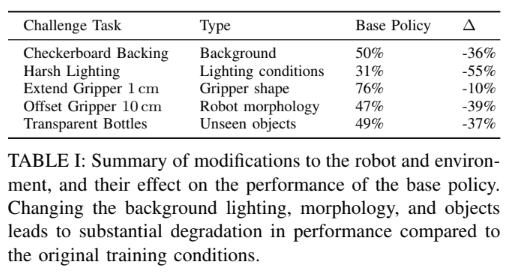
- image-based grasping policy to changes in background, lighting, object shape and appearance,
- robot morphology and kinematics like extending the gripper and offsetting the gripper.
They have had 2 major contributions from this work -
- A careful real-world study of the problem of end-to-end skill adaptation for a continuously-learning robot
- Evidence that a very simple fine-tuning method can achieve that adaptation.
Their claim -
“To our knowledge, this work is the first to demonstrate that simple fine-tuning of off-policy reinforcement learning can successfully adapt to a substantial task, robot, and environment variations that were not present in the original training distribution (i.e. off-distribution).”
Pre-training process
They train the base policy using QT-Opt[1] algorithm (not going through the algorithm to train the policy can go through the paper).

Firstly the training is done offline using 580k grasps of around 1k objects, and then online training with 28k grasps on the same corpus of objects.
This yields around 96% accuracy for previously seen objects and around 86% accuracy on a subset (6 objects) of objects which they consider hard to grasp.
So now next they check the robustness of the baseline policy on various task, the first number is the performance of this baseline policy.
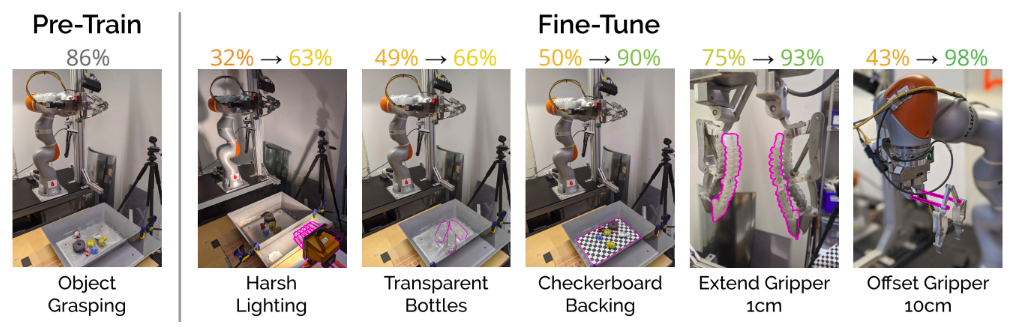
Pink color in the Challenge tasks is the change they made.
Interesting things from this baselining -
- When they offset the gripper by 5cm there is no change in the accuracy but if they increase it to 10cm there is a considerable drop in the accuracy.
- When the objects (opaque) were picked that were not in the object set the policy seemed to perform great (98% accuracy), but when transparent bottles were used the policy performed poorly (49%)
Finetuning process
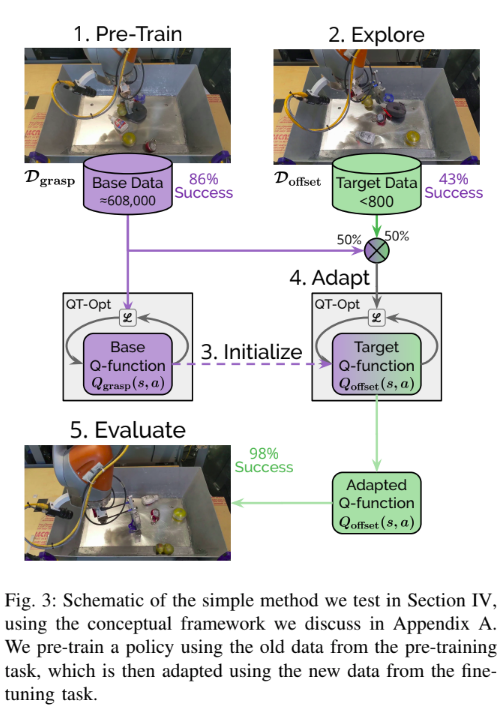
So to finetune the algorithm requires a very small amount of data compared to training the baseline policy.
They use the pre-trained policy (1 from the figure) to explore the new task.
Initialize the new policy and other parameters with the pre-trained one, and the buffer will have both the original task and the new “challenge” task.
Update the policy now using the training algorithm (QT-Opt one) and initially we sample trajectories from the original and new task with equal probability for some number of update steps.
Then finally they evaluate the learned policy on the target task
Summary of Results for finetuning
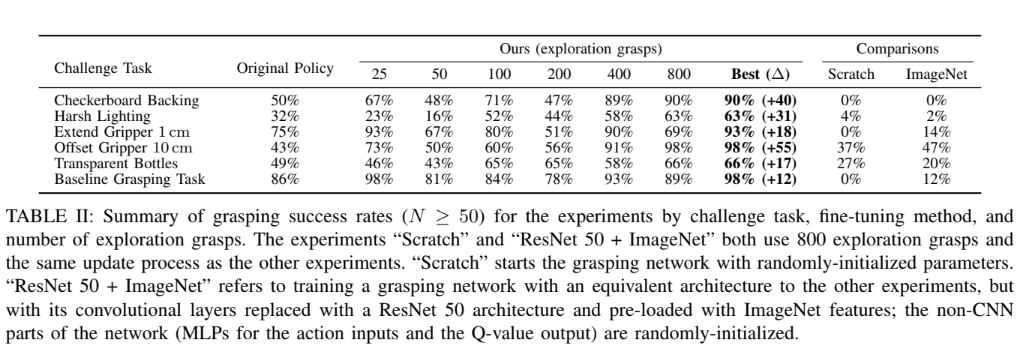
They started with 25 grasps for finetuning, and so on. And 800 gave satisfactory results.
For evaluating they have used 50+ trajectories and they shuffled objects in the bin.
There is a general trend that more the grasps more the accuracy except at 200 where it is lower (this can be because of the number of gradient steps they used more on this later)
Continual Learning
Now that the policies have been evaluated independently on various tasks. They move on to learn a continual policy
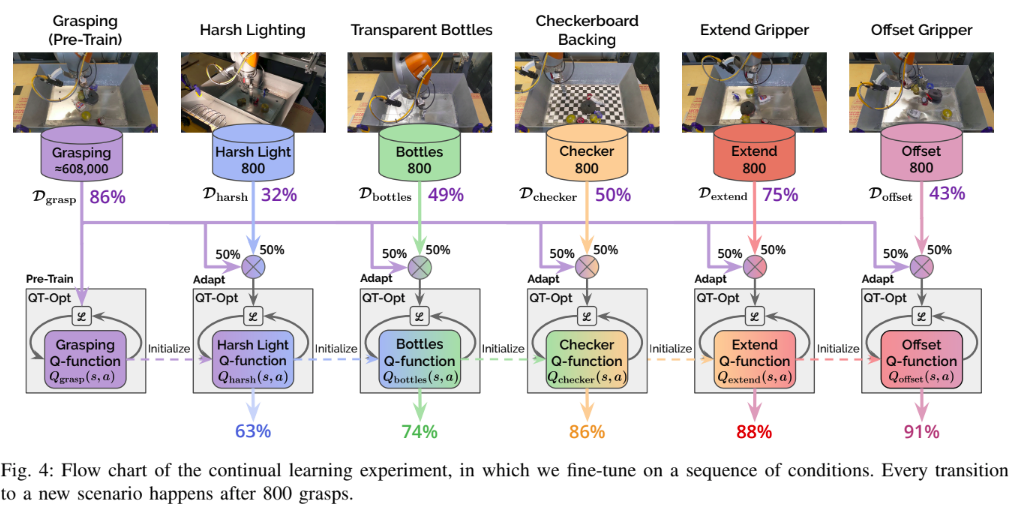
The training process is very similar to the finetuning one, the “base policy” updates for the target task. For e.g. for the Transparent Bottles task, the base policy will be the policy that was finetuned for the Harsh Lighting task.
Summary of Results for continual learning

Some insights-
-
We see there is a huge difference between single and continual learning task, this might be because of a lower number of trajectories use, but for new work, these are great results. (This is a dilemma discussed later)
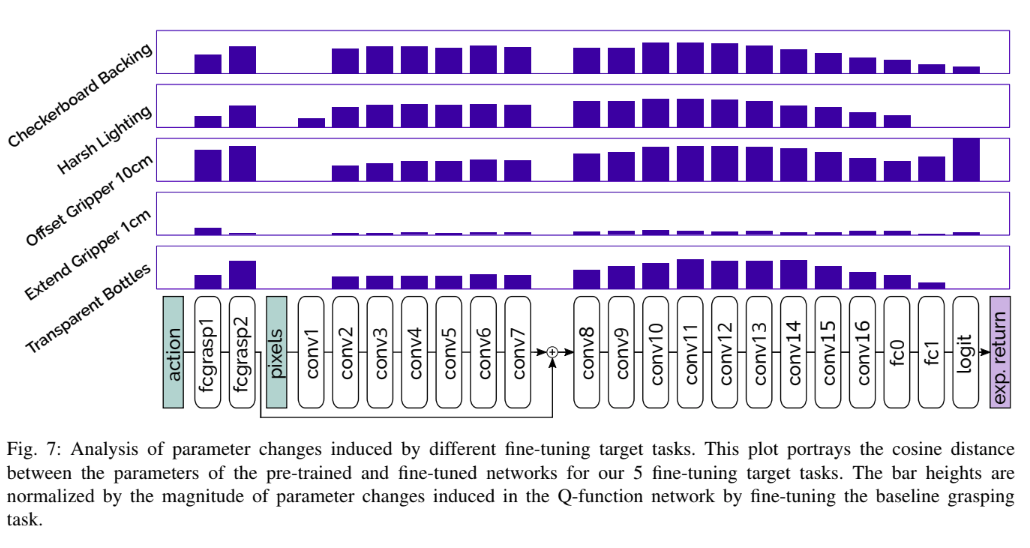
Comments
There are some dilemmas in training such robotic systems, one such dilemma is the number of trajectories used in training the policy offline. There is no such metric to gauge the accurate performance of the policy in the real world. The performance can only be tested once it has been deployed. Evaluating on a robot is a long and time consuming process and cannot be done multiple times.

We can see this in this study that they did, increasing the number of gradient steps does not necessarily mean that the model will learn more. So they fixed the number of gradient steps to 500k steps (this might not be optimal)
References
[1] Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on Robot Learning, pages 651–673, 2018.