paper-reading-group
Convolutional Networks with Adaptive Inference Graphs
Authors: Andreas Veit, Serge Belongie
Year: 2018
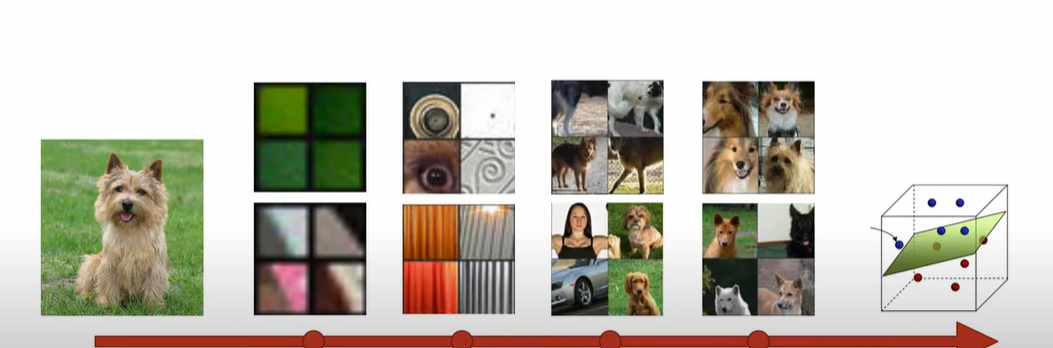
Majority of features of a CNN are these high level features that are not relevant to the image.
Theme-
Why does convolution layers have a fixed feedforward structure?
Instead of Image being passed through hundreds of layers why couldn’t image be directed to first high level features (initial layers) then fine grained differences that is specifically designed for this class.
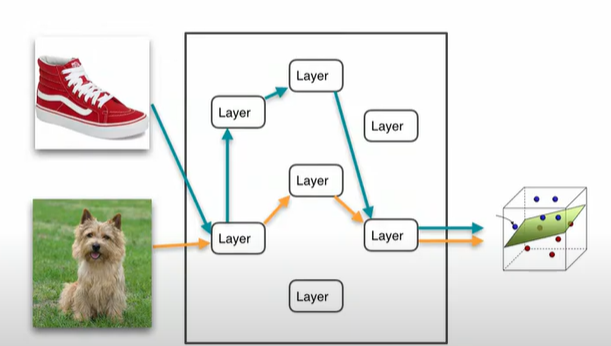
This paper proposes the idea of - the more a network already knows about an image, the better it should be at deciding which layer to compute next, so the architecture ConvNet-AIG decides for each input image on the fly which layers are needed. What if, after identifying that an image contains a bird, a ConvNet could move directly to a layer that can distinguish different bird species, without executing intermediate layers that specialize in unrelated aspects?
Solution proposed to this idea - A gated mechanism should be attached to each residual layer which makes a discrete decision on whether the image should be passed through it or not. This idea was supported by a study which showed even after removal of few residual block in a fully trained model, the performance of the model didn’t drop much.
Related work-
- Similar to dropouts but for layers instead of neurons
- Kind of hard attention mechanism - focus more on one layer than the other. (Hard attention)
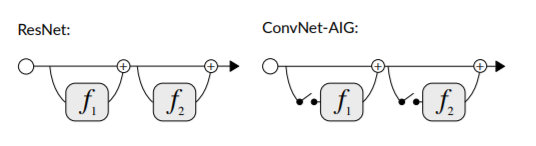
Gated Inference
The architecture follows the basic structure of a ResNet with the key difference that instead of executing all layers, the network determines for each input image which subset of layers to execute. In particular, with layers focusing on different subgroups of categories, it can select only those layers necessary for the specific input.
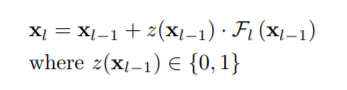
Gate can be split into 2 parts
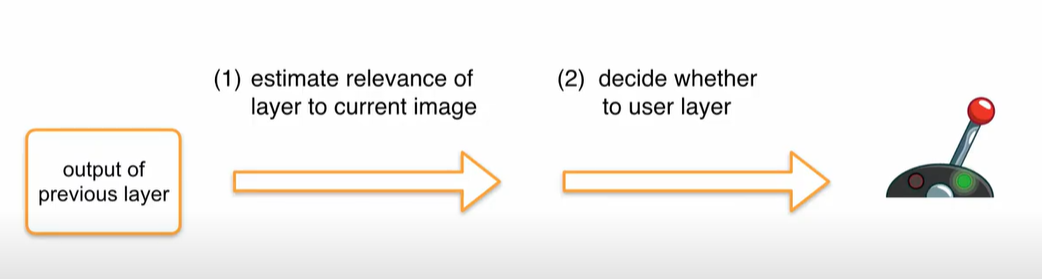
- First half (estimating relevance) creates a relevance score using the input of the previous layer, downsampling it using global average pooling just to reduce computational cost.
- Second part of the gate, depending upon the relevance score it decides whether the layer should be executed or not.
Problems with this Gates -
- Mode Collapse - The gates might collapse into trivial solutions - such as always or never executing the layer. Solution - Adding Noise to the system.
- Gradient propagation - The gate needs to give discrete output of 1/0 which would cause a problem which gradient calculation. Solution - Gumble softmax, Forward pass discrete value, backward pass SoftMax.
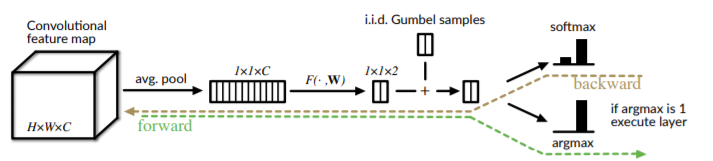
*for math and gumbel samples have a look at the paper
Loss Function-
They also introduce a target rate loss, which pushes the network to execute t percent of all layers. This is to prevent the scenario where the model uses all the layer or very few of them.
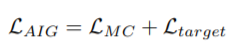
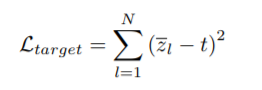
Let z’l denote the fraction of images within a mini-batch that layer l is executed.
Experiments/Results-
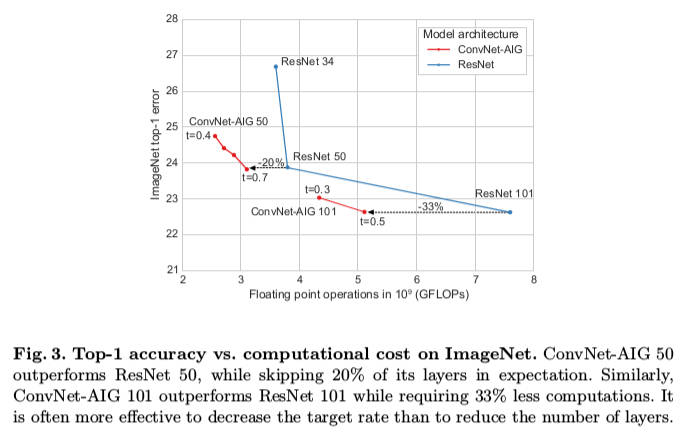
ConvNet-AIG 110 clearly outperforms ResNet 110 while only using a subset of 82% of the layers.

This image signifies that even of the same category if the classification of that object is difficult it would use much more layers than that of an easy image of the same category.
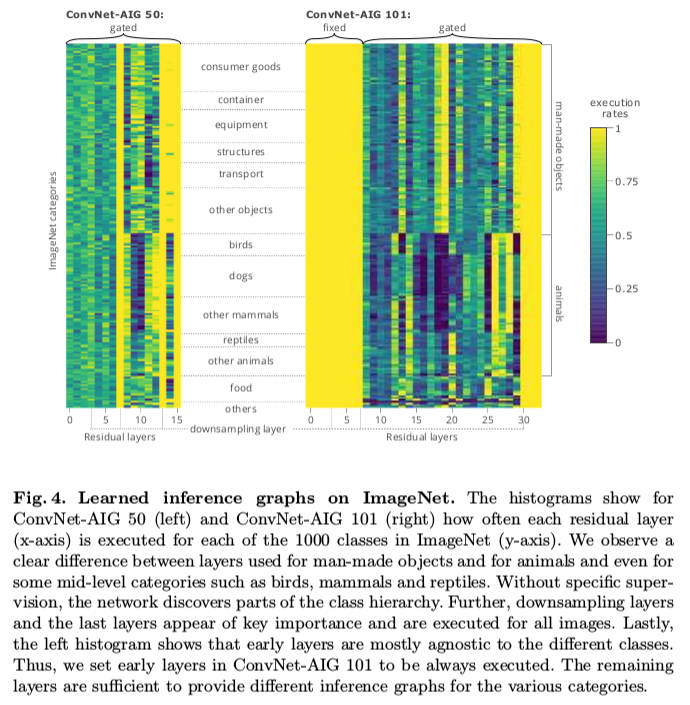
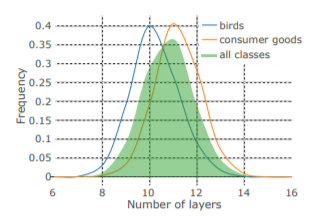
It can be seen that for Birds (in general living animal) one less residual block is needed to compute than that of the man made objects. Which implies lesser computational time.
Conclusion -
- ConvNet dont need a fixed feed forward structure. They can adaptively generate inference graphs for on an imput image
- ConvNet-AIG improves efficiency and reduces the computational time and FLOP.