paper-reading-group
DeepSynth: Automata Synthesis for Automatic Task Segmentation in RL
https://arxiv.org/pdf/1911.10244.pdf
Mohammadhosein Hasanbeig, Natasha Yogananda Jeppu, Alessandro Abate, Tom Melham, Daniel Kroening (CS Department, University of Oxford)
Background
Motivation
- Tasks with sparse rewards are difficult for current RL methods (e.g. Montezuma’s Revenge)
- Such tasks are usually made up of multiple sequential subtasks for which direct reward isn’t given
- No efficient way to break down tasks. (E.g. Cooking pasta = boiling pasta + chopping vegetables + making sauce + combining pasta and sauce + serving on the plate)
- RL methods do not currently have a way to incorporate memory efficiently.
- No way to transfer learned information about the structure of the task between agents.
Previous Work
- Hierarchical RL and Options
- Requires either explicitely specified high level actions or intermediate supervisory signal
- Not very sample efficient
- Learned structure not always human interpretable
- Using Linear Temporal Logic to give constrain to the agent.
- Reward Machines:
Automata

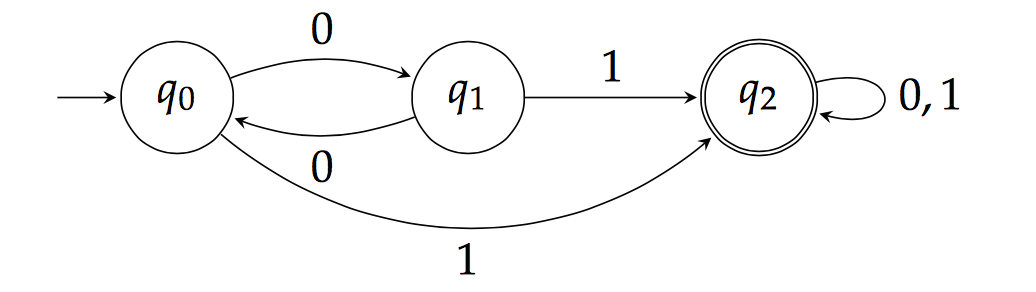
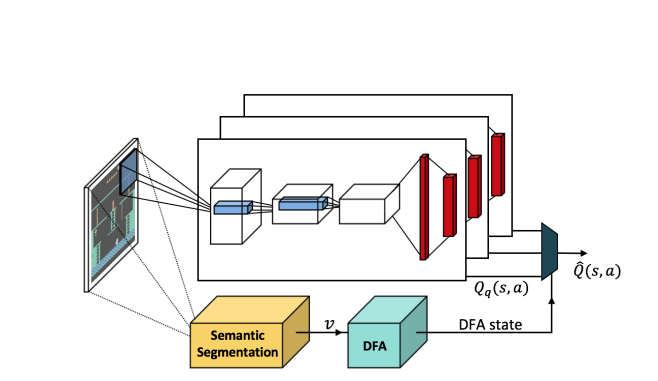
What does DeepSynth do?
- Uses automaton to choose which policy is used and what reward to give to the agent
- Learns automaton from traces colleted by agent which exploring
DeepSynth Architecture
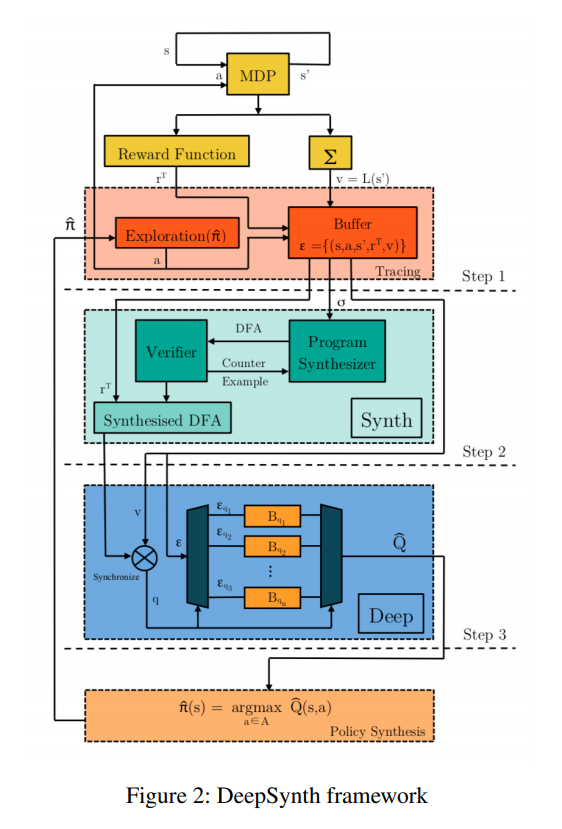
Tracing
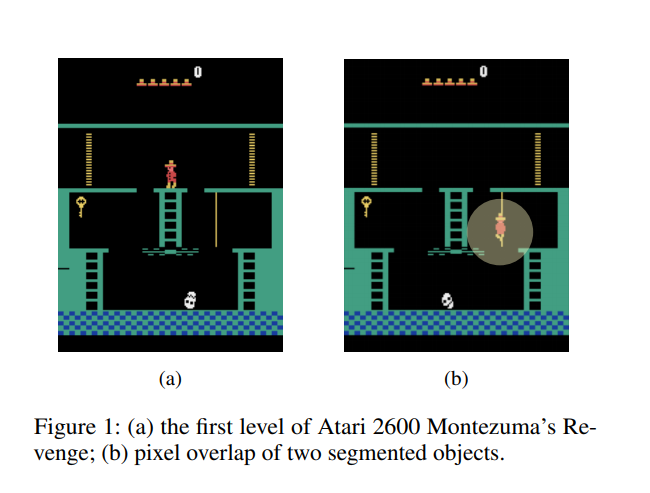
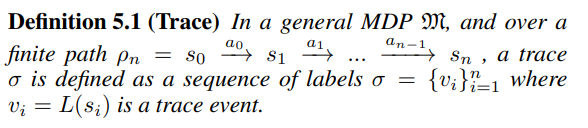
- Trace is sequence of labels of states encountered during agent’s interaction with the envrionment
- Labelling function $L : \mathcal{S} \rightarrow 2^{\Sigma}$ uses image segmentation to label each pixel in the observation with its segment. The output of the function is the set of labels of the segments which overlap with that of the character. E.g. {right_ladder}, {key} etc..
Automaton Synthesis
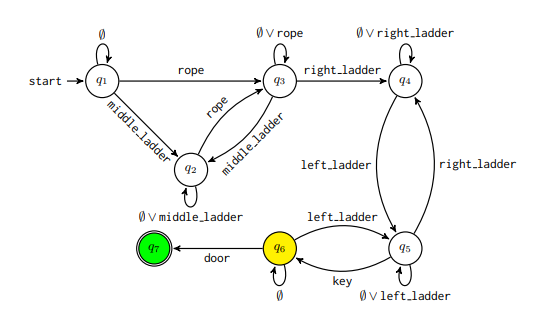
- Given a set of traces, a Deterministic Finite Automaton in constructed by perofming a search.
- Each trace is divided into segments of some predefined length $w$ which controls runtime of the algorithm
- After automaton is generated, a verification is performed. All transition sequences of some length $l$ are verified to be subsequences of the trace. So higher $l$ means more strict verification
- Automaton is grown from N = 2
RL

- Product MDP is defined to synchronise the actually MDP of the game and the constructed DFA of the agent
- Each state in the DFA can be though to correspond to a sub task.
- Multiple DQNs, each corresponding to a state of the DFA are used.
- Action chosen though epsilon greedy
- Reward given to the agent is combination of intrinsic reward and reward from the envrionment
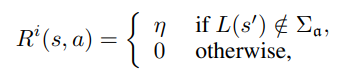
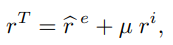
- Intrisic reward motivates agent to explore outside the DFA
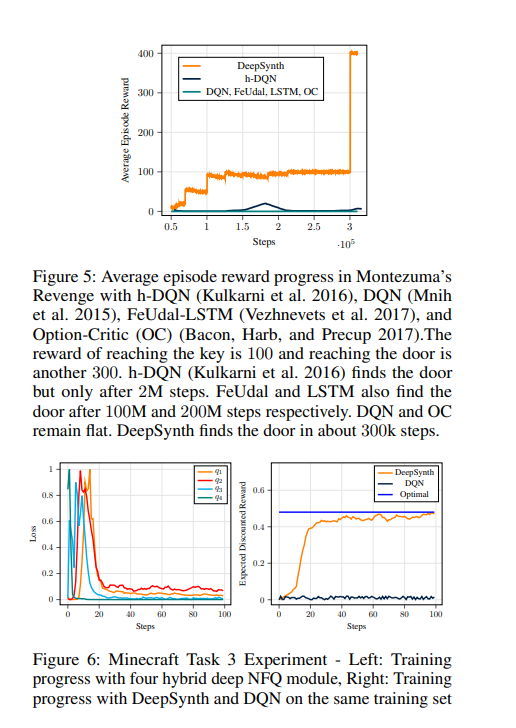
Experiments
Further Discussion
- How can we learn the object detection and generalise it to higher level features than just objects
- How can automaton be used to transfer knowledge between agents
- Puting limits on automaton for Safe RL
References
Logically Constrained RL - https://arxiv.org/abs/2002.12156
Reward Machines - https://arxiv.org/abs/2010.03950