paper-reading-group
Accelerating Reinforcement Learning with Learned Skill Priors (SPiRL)
Authors: Karl Pertsch, Youngwoon Lee, Joseph J. Lim
Code: https://github.com/clvrai/spirl
Website: https://clvrai.github.io/spirl/
Motivation
- RL agents often learn all the tasks from scratch, even if they are related, as contrary to humans which are able to leverage experience from learning other similar tasks
-
Ample unstructured data available in domains like autonomous driving, indoor navigation, etc.
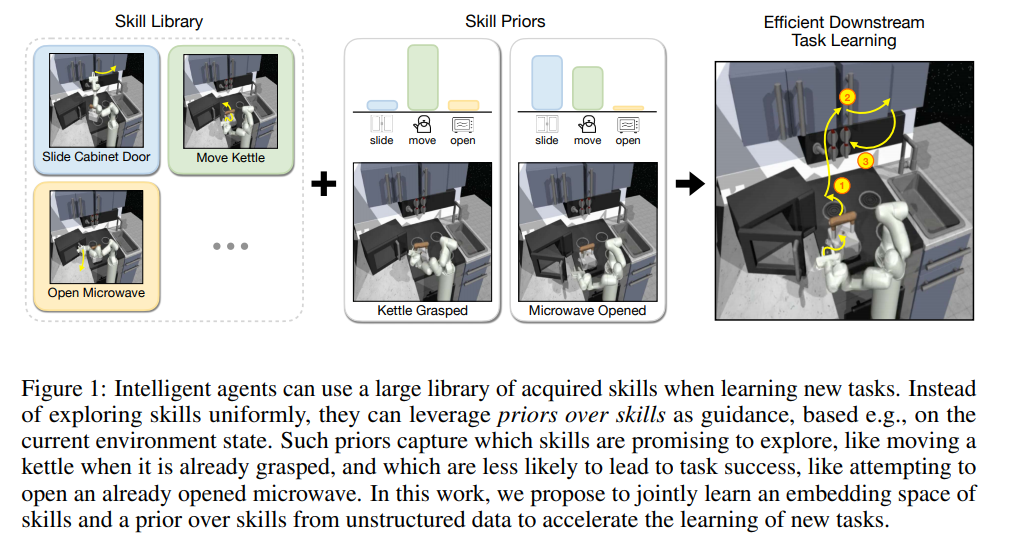
Previous Work
- Extracting skills from unstructured data and leveraging them for downstream learning tasks
- Meta Learning Approaches - Online Learning, Require a defined set of learning tasks
- Learning skill embeddings
Contribution
Leveraging skills embeddings from large offline datasets and learning a prior over them for efficient downstream learning tasks
Methodology
Learning the Embedding Space and the Prior over the embeddings
- Use already available large datasets having trajectories for a related task using offline reinforcement learning
- Skill - A finite sequence of temporally contiguous actions
-
Use random clippings of length $H$ from the trajectories from the offline dataset
$a_i = [{a_t}^i, {a_{t+1}}^i, ....., {a_{t+H-1}}^i]$ -
Learning the skill embedding space $Z$ by learning the model $p(a_i z)$ by maximizing the ELBO :
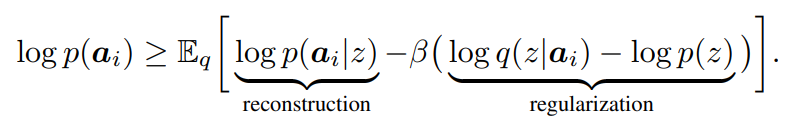
- $p(z) \sim \mathcal{N}(0, 1)$
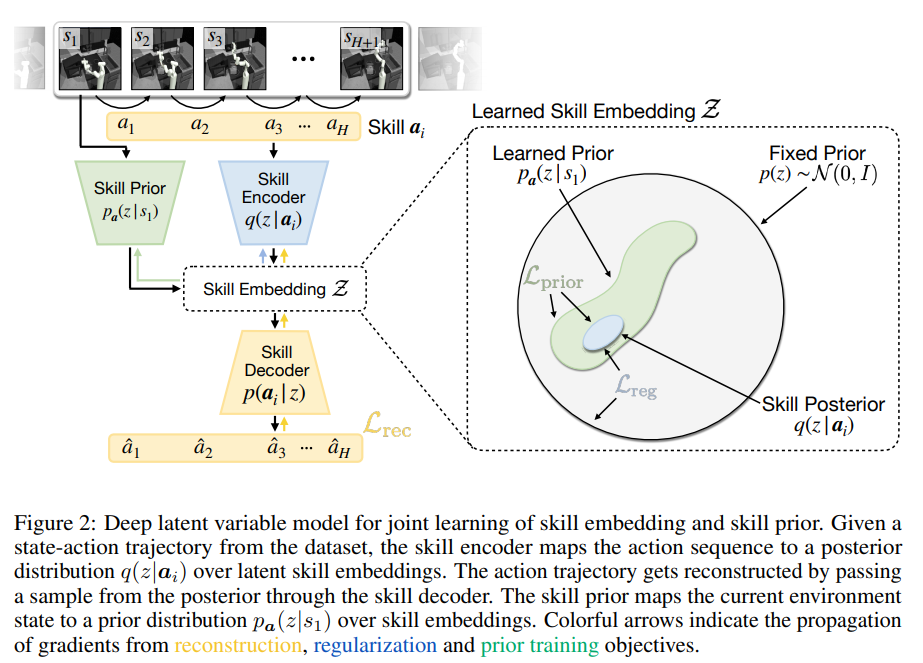
- Using the KL Divergence Loss to learn the prior over the
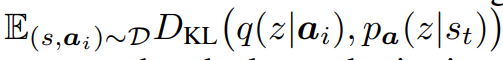
Using the prior over the skills for downstream reinforcement learning tasks
- Replacing one-step reward with H-step reward and single step transitions with H-step transitions
-
Learning the policy over the embeddings instead of the actions for model-free reinforcement learning $\pi_\theta(z s_t)$
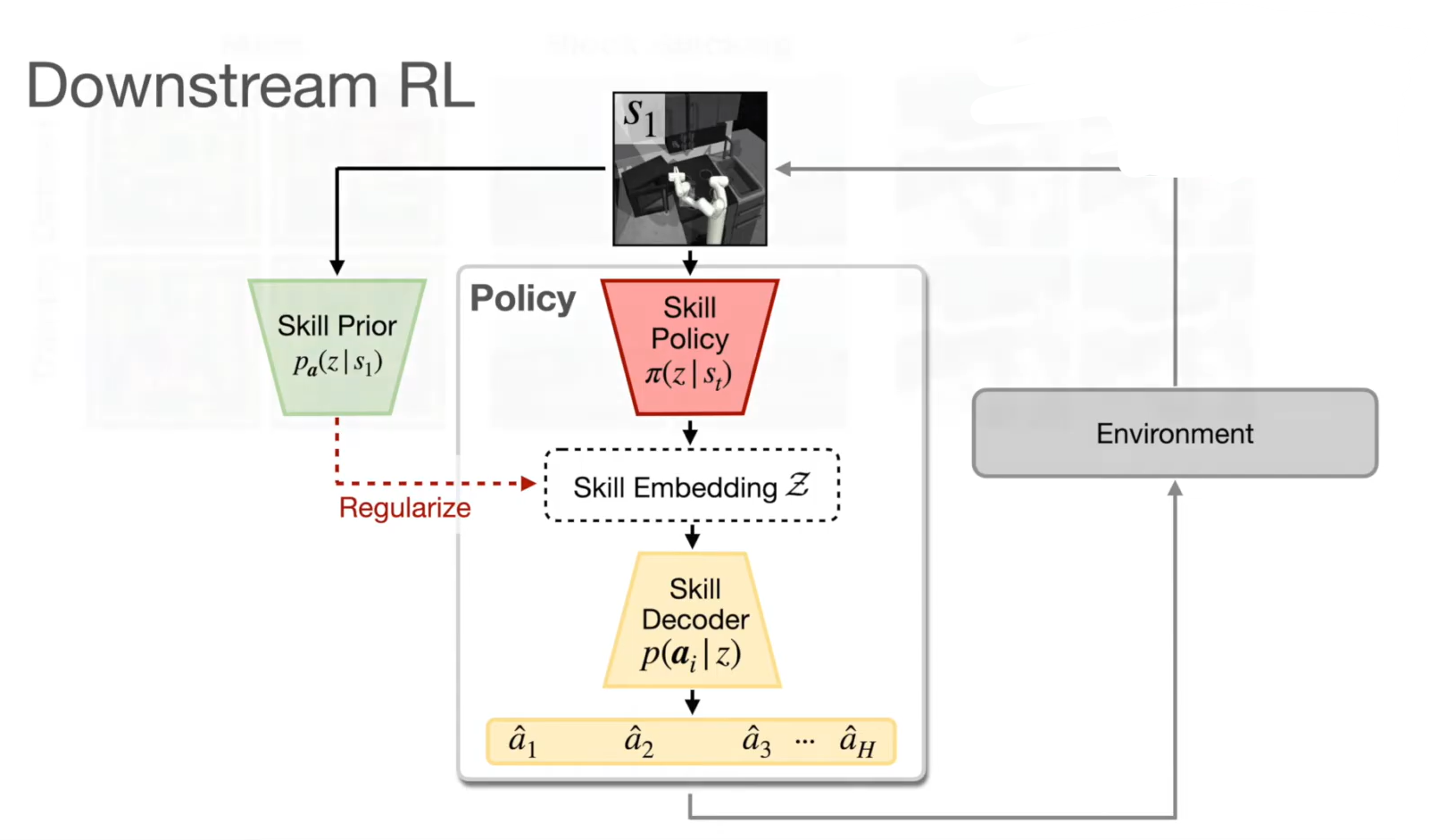
- Integration with maximum entropy RL framework
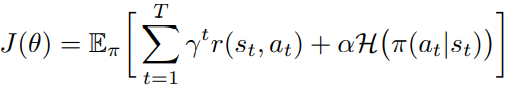
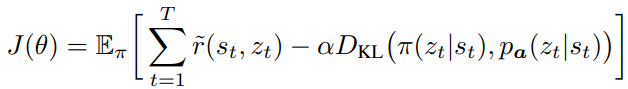
Experiments
- Results have been reported for Soft-Actor Critic
- Three environments
- Maze navigation - D4RL
- Block Stacking
- Kitchen Environment - D4RL Benchmark
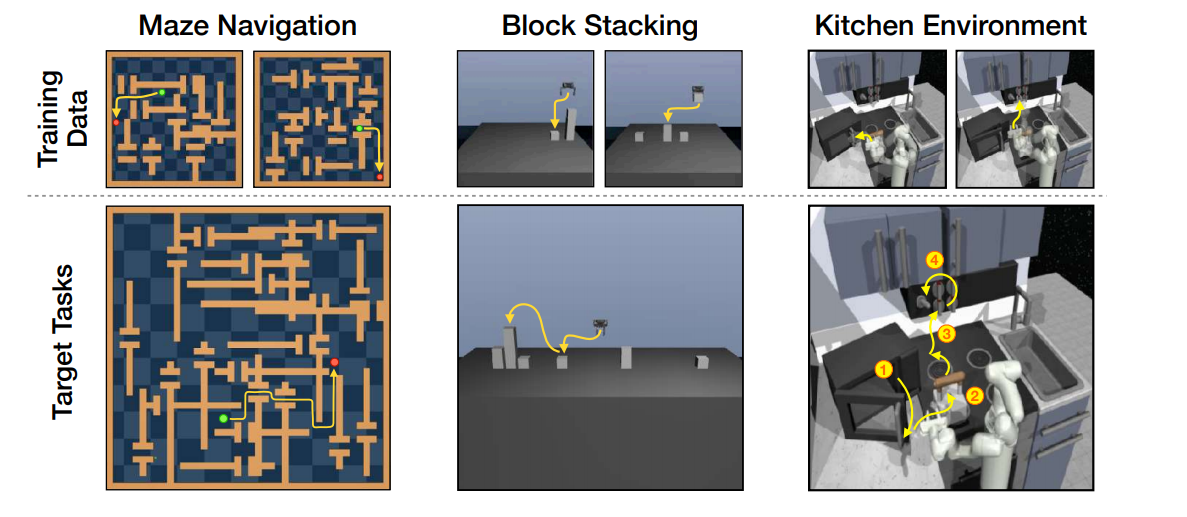
- BLOCK STACKING ENVIRONMENT

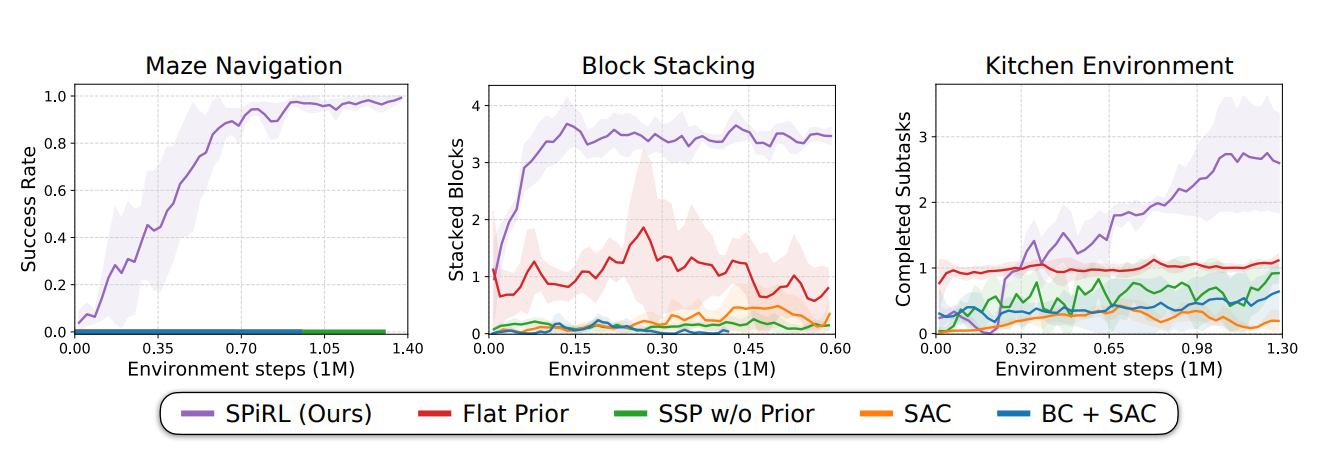
- PERFORMANCE
- SPiRL - Skill Prior Reinforcement Learning
- Flat Prior - Single Action Prior without temporal abstraction
- SSP w/o Prior - Learned skills without any prior
- BC + SAC - Learning a Behavior Cloning Policy from the offline data and finetuning it in the downstream RL task using SAC
- SAC - Soft Actor Critic
- EXPERIMENTS OVER DIFFERENT HORIZONS (ABLATION STUDIES)
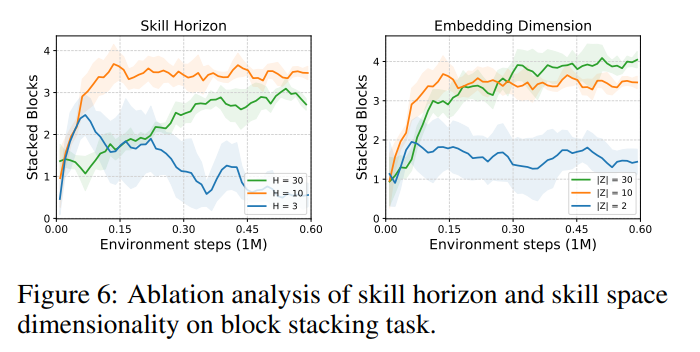
Further work
- Experimenting with learning skill priors conditioned on different things; the paper reports results with the priors conditioned on the current state
- How does this approach scale with multi-task learning (continual learning agents)?